
Transformers Part I: Bonobos and Machine Language
Want to dive into LLMs but don’t know where to start? I got your back. From word embeddings to logits, this is everything you need to know about the Transformer
Honestly, I don’t know jack shit about AI.
To me, a “transformer” is either an Autobot or a Decepticon. But like a half-blind man groping in the dark for a light switch, I spent 31 days deconstructing the architecture behind the AI revolution. And now, I will share what I learned with you so you don’t have to spend a day of research.
Introducing: the Transformer (Part 1 of 2).
You’ll understand what the transformer does, how it works, and why it’s so important.
To get the most out of this article, you should have a basic understanding of computers. Previous experience with computer science and linear algebra is helpful, but not required.
By the end of this series, you’ll know everything I know and you’ll have all the resources I used so you can learn more and get deep into the math.
Let’s get into it 💥
Transformers

Kanzi the Bonobo
In the 1980s a bonobo named Kanzi learned how to communicate with humans using a keyboard of symbols. Researchers asked Kanzi questions and Kanzi responded. They also gave him a series of commands and he would perform them. Here’s an example keyboard that Kanzi used.

In one scenario, Dr. Sue Savage-Rumbaugh asked Kanzi to go get the carrot in the microwave, Kanzi went directly to the microwave and completely ignored the carrot that was closer to him. Kanzi could comprehend both terms: “carrot” and “microwave”, and understood the context of the command.
Kanzi understood that the symbols were associated with certain actions and nouns. When he used "strawberry" it could mean a request to go to where the strawberries grow, a request to eat some, it could also have been as a name, and so on.

But he was unable to use language as effectively as humans. (https://search.worldcat.org/title/848267838)
First, he had trouble using morphology. Morphology is the modification of words to achieve a new meaning, like adding an “s” to the end of a noun to make it plural. Without this ability it’s difficult to understand relationships between words.
Second, Kanzi had difficulty generating recursive sentences. Recursive sentences are sentences that contain a sentence within it. For example, “Dorothy thinks witches are dangerous” is a recursive sentence because there is a stand-alone sentence (“Witches are dangerous”) within it. Kanzi had difficulty creating them. So, there was an upper bound on the length of Kanzi’s sentences.
Kanzi could grasp the basics of language, but was unable to pull apart the nuances in it.
Humans have overcome the limitations that Kanzi faced. So has AI.
The Problem: It’s all Greek Sequences to me
In machine learning, there is a set of problems called sequence modeling and transduction. This class of problems includes language modeling and translation. But many problems fall in this category.
“Many machine learning tasks can be expressed as the transformation—or transduction—of input sequences into output sequences: speech recognition, machine translation, protein secondary structure prediction and text-to-speech to name but a few.” — Sequence Transduction with Recurrent Neural Networks, 2012.
Namely, anything that requires understanding the relationship between “tokens” or that requires the generation of a sequence of tokens.
Tokens are atomic pieces of a sequence. They are the smallest, non-divisible element in a sequence. And sequences can be anything from a string of DNA to a sentence.
For example, in English, a sentence like:
“The dog ran happily.”
Would be split into the tokens:
[“The”, “dog”, “ran”, “happi”, “ly”, “.”]
Notice the modifier “ly” and the period are tokens. But in general, you can think of tokens as words. I’ll use them interchangeably throughout the rest of the article.
We’ll talk more about real-world problems the transformer solves at the end, but suffice to say: sequence modeling solves many of them.
In any case, the original transformer was designed to solve transduction—a fancy word for language translation done by a computer—so we’ll focus on that.
Transduction
Most sequence transduction models have an Encoder-Decoder structure. Where the Encoder extracts features from the input sentence, and the Decoder uses those features to generate the output sentence.
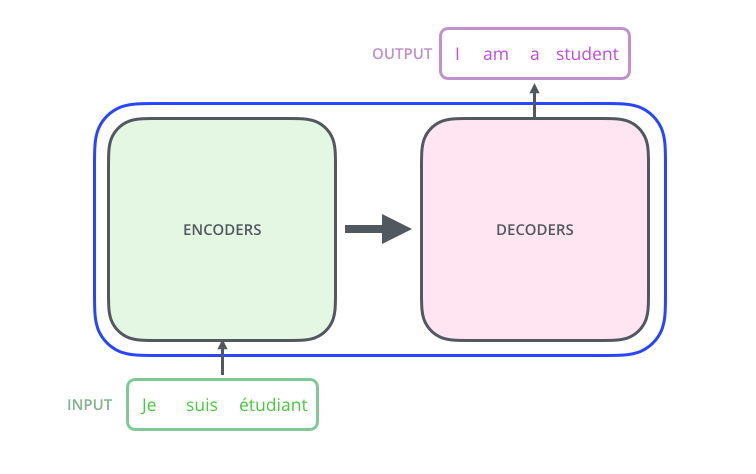
This is the high-level structure of the transformer architecture.
Briefly, Recurrent Neural Networks (RNNs)
To understand why the transformer is special we have to understand what came before it.
The previous state-of-the-art architecture was the Recurrent Neural Network (RNN). These models sequentially predict the next token based on everything that came before it. They do this by using a vector (a row of numbers) to store information about the words that were previously processed. This vector is often referred to as the “hidden state” or “memory”.
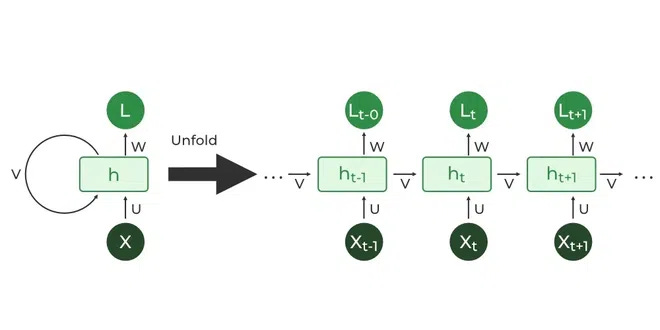
Imagine we’re processing the example sentence: “The dog ran happily.”
Each word must be fed into the RNN to get the next translated word. This creates a bottleneck on the model, where the time to complete the task is limited by the time it takes to process one word. If it takes C time to process a word, and you have N words, the total processing time is O(CN).
Problems with RNNs
Broadly, RNNs have two challenges:
One, training takes a long time.
RNNs have a bottleneck on training that scales linearly with the input size. Sentences are processed word by word because each token depends on the result of the previous computation. This is true for encoding and decoding stages.
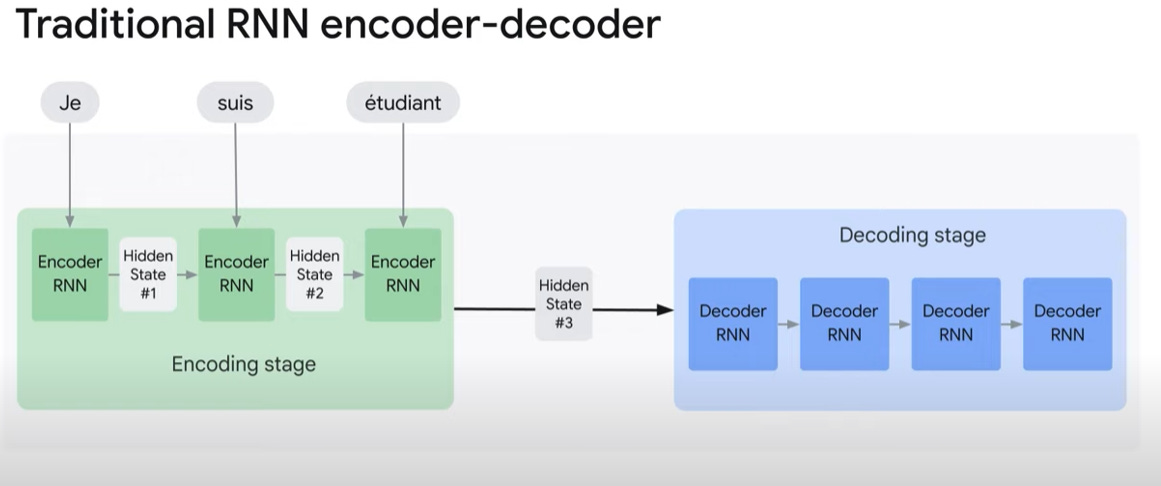
Two, the model has a bad memory. It will often forget context when generating the next token in the sequence.
RNNs use a single vector to store information about the previously processed word. So, as the input gets longer, words at the beginning of the input have a diminishing impact on the current “next word” (especially compared to recent words). This is a kind of vanishing gradient problem.
RNNs have short-term memories. You can make optimizations at the edges, but it’s a nontrivial problem.
But what if there was a way to make the model faster and improve memory? That’s the power of the transformer.
Now that we have the background covered, let’s dig into the transformer’s details. We’ll start at the beginning: the inputs.
Feeding the Network: The Inputs
First, we have to break down our input sentences into something that computers can understand. Computers don’t really understand meaning or syntax, but they understand numbers.
In fact, neural networks are just large, non-linear functions. The network takes a lot of numbers and does some math on them (matrix transformations) to produce a result. To boil it down, neural networks are just functions: f(x) = y.
So we break our pre-translated sentence into tokens. Then we turn those tokens into numbers that the model can use.
But what number should a token get?
We could simply assign each word an identifying number, but that doesn’t really give us much more information aside from uniqueness.
Lucky for us, we can add more information to our words using a technique called “word embeddings”. We turn each token into an embedding.
Each embedding is a vector that represents the word. Each vector is just a list of numbers between 0 and 1.
These embeddings give the word “meaning” that the model can process. It creates a base-level of understanding that the model uses to determine relationships between words.
So we go from words → tokens → vectors, with each vector having some “meaning”.
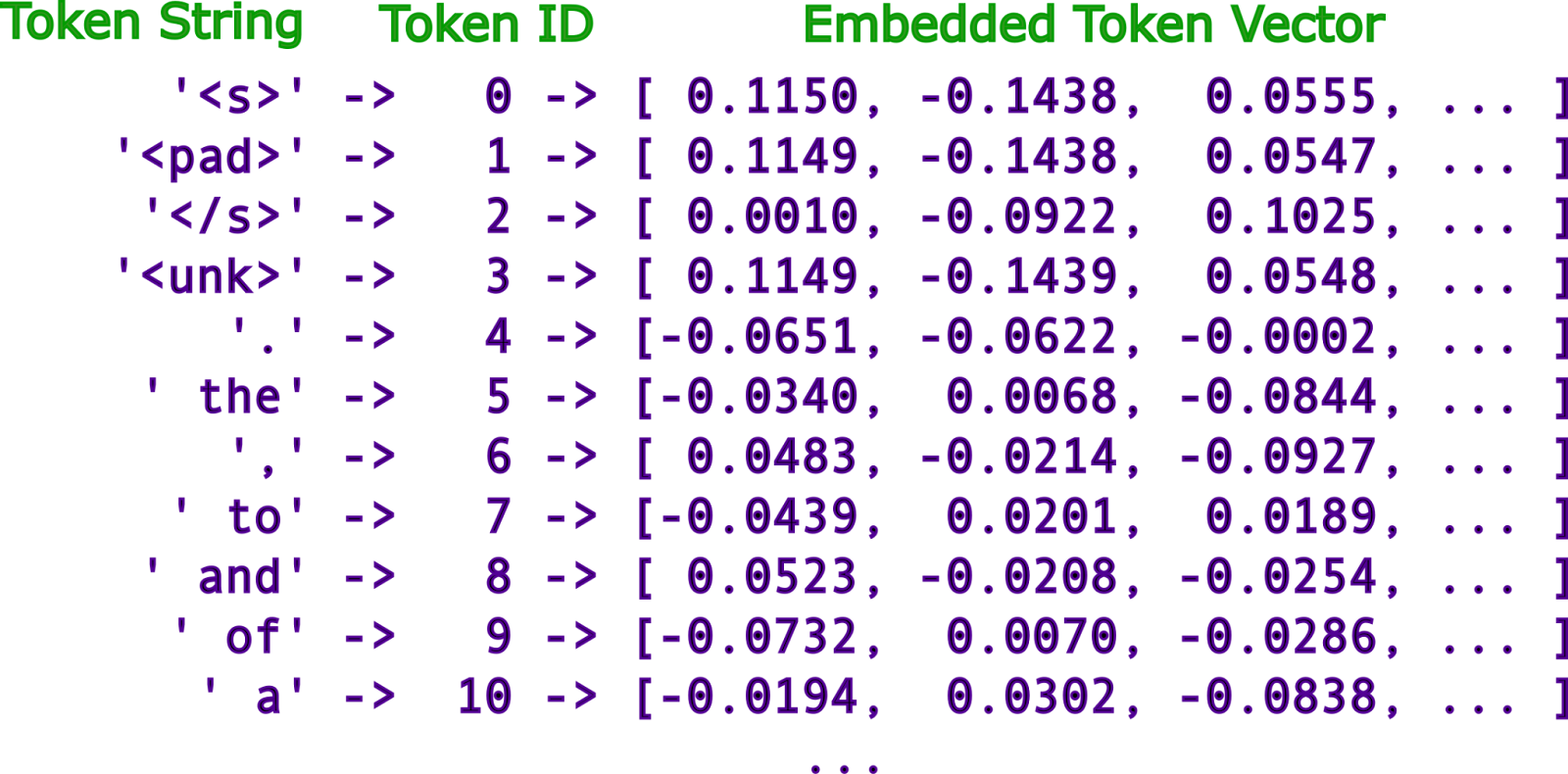
This is the core idea behind word embeddings: similar words have similar vector values, and words are “similar” if they are often used in the same context.
These are similar pairs of words:
dog & cat
carrot & celery
run & walk
Notice that if you use a word from one of the pairs in a sentence, you can replace it with its pair and the sentence still makes sense.
“My pet dog ate breakfast.”
“My pet cat ate breakfast.”
So the meaning of a word is defined by the context in which it appears.
“You shall know a word by the company it keeps!” - John Firth (“A synopsis of linguistic theory 1930-1955“)
Embeddings are generated by processing lots of sequence data (in our case text).
The most common way to generate word embeddings is to use Word2Vec developed by Google in 2013. This is the primary technique for all natural language processing (NLP) problems.
But the transformer learns its own embeddings from scratch. The weight matrix is randomly initialized and refined as it trains.
Once we get these vectors, we apply “positional encoding” to the list. This marks each vector so the model can “see” (and then learn from) the relative order of words.
So, words are
Broken down into tokens
Which are broken down into embeddings—that encode some meaning
Finally, we mark the vectors so the model can understand word order.
This final list of vectors is fed into the transformer as input. And the first step inside the transformer is the encoding component.
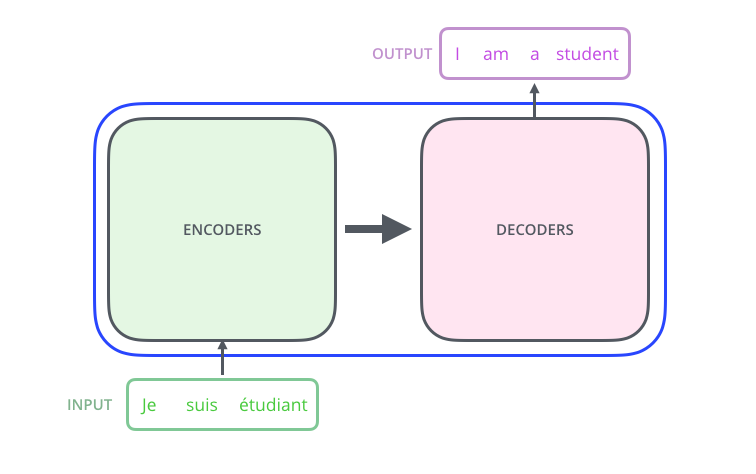
The Encoder
The role of the Encoder is to extract features (meaning) from the input sentence. Note that the Encoder and Decoder components are actually stacks of encoders and decoders where each encoder is identical in structure and each decoder is identical in structure.
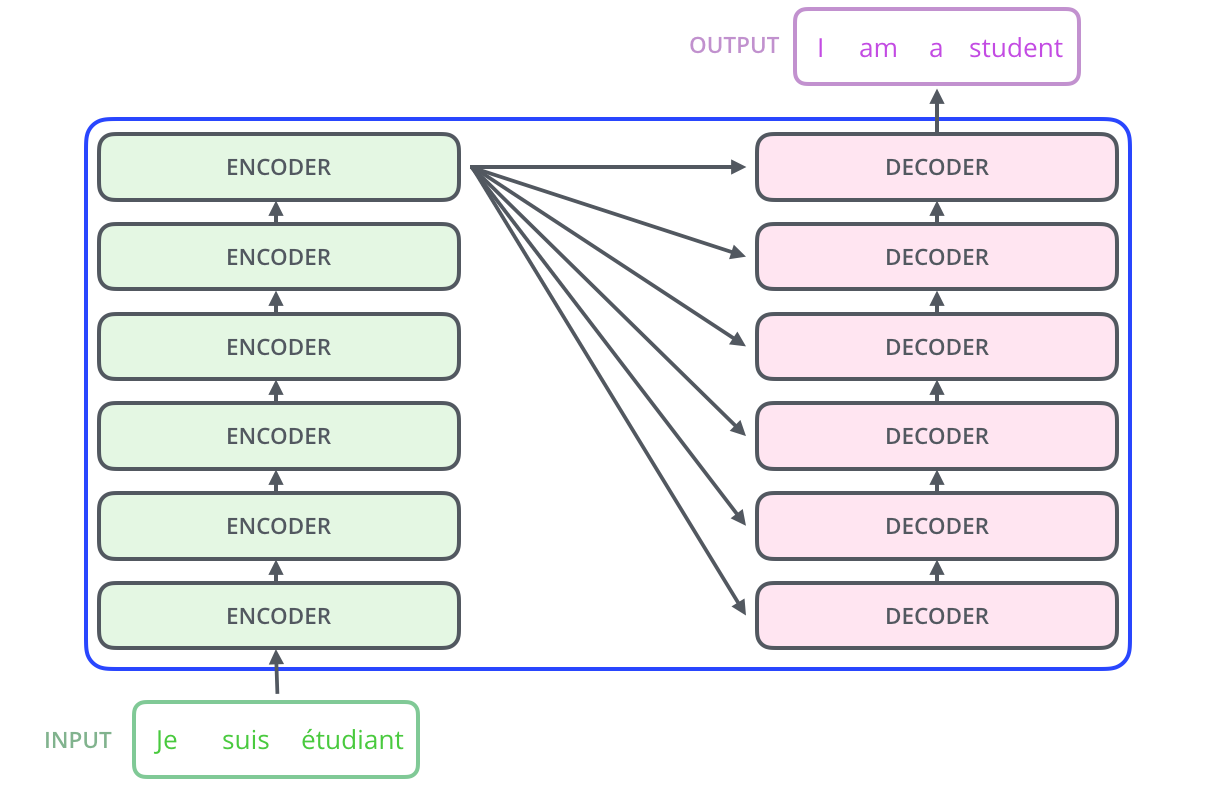
I make a distinction between “Encoder” and “encoder”. When I refer to Encoder, I mean a group of smaller encoder units. This distinction isn’t in the paper, but it’s helpful to define them separately.
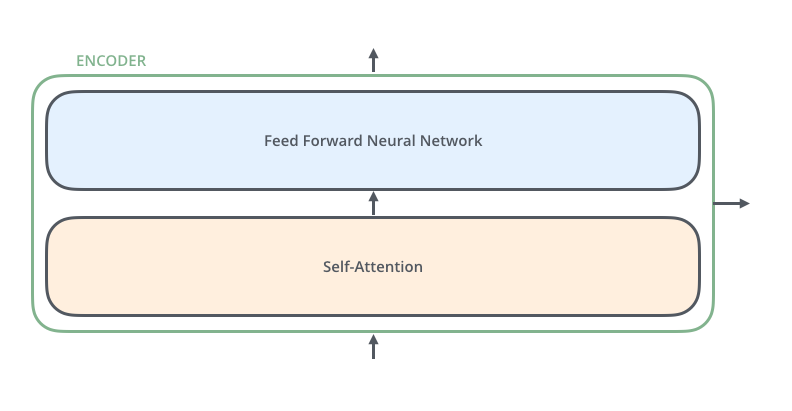
In the paper, the Encoder is composed of 6 identical encoders. Inside each encoder are two sub-layers:
The Self-Attention layer
The Feed Forward Neural Network
The decoder units are also identical to each other (but are distinct from encoder units).
I know this might seem complicated but the encoder and decoder are almost identical. Once you get the encoder, all you need is a few small pieces to get the decoder.
And this is where things get interesting.
Self-Attention
Self-attention is the part of the transformer architecture that stands out from other models. Before, the self-attention mechanism was just one component of a model’s architecture, but the transformer authors made it the only component. Hence the title of the paper: Attention Is All You Need.
The purpose of the self-attention mechanism is to make the model understand relationships between tokens—and encode that meaning into the vector. Given a word and the context around it, what does the word mean?
I’ll release Part II next week. Stay tuned!
And as always, please give me feedback on X. Which one was your favorite? What do you want more or less of? Other suggestions? Please let me know. Just send a tweet to @JakeAndStake.
Much love.
Jake